摘要
在 Ubuntu24.04 上,使用 containerd 作为容器运行时,安装多节点的 Kubernetes。
前言
经过几天的准备之后,我们已经具有快速搭建多份高一致性的运行环境的能力了,现在,让我们来部署我们最重要的管理平台:kubernetes。
背景知识
首先,我们今天要安装的是 k8s 的官方版,其他各种发行版再怎么强,也都是从原版改进而来的。把原版搞定了,其他的自然就简单了。(其实是 CKA 要求使用原版,不然谁闲的没事干折磨自己)
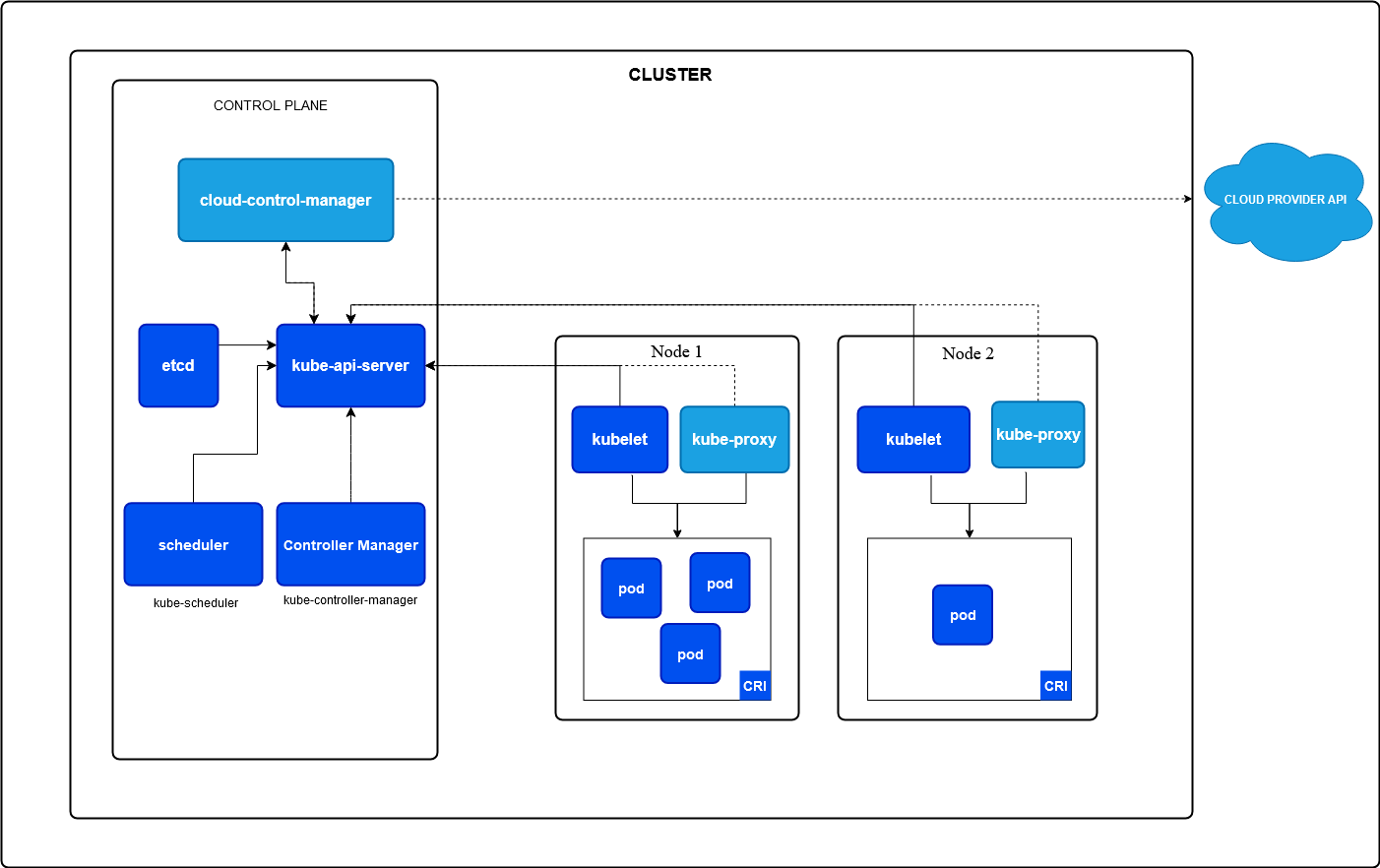
Kubernetes 是什么?
kubernetes,简称 k8s,是一个模块化的容器的编排平台。可以对容器在更高维度上进行管理,可以更好的服务应用程序的部署。
k8s 是一个模块化的平台,其各个功能模块都高度抽象为接口,交由其他组件实现,而 k8s 只负责最核心的容器编排的工作。例如:
- CRI (Container Runtime Interface):
容器编排首先得有容器运行的环境,CRI 定义了管理容器的操作。常见的实现有:contianerd,cri-o,dockershim
- CNI (Container Network Interface):
容器需要对外提供服务,所以还需要有网络,k8s 定义了一套网络模型,CNI 是实现规范需要实现的接口。CNI 插件负责配置容器的网络,使容器能够安装规范进行通行。常见的实现有:Calico、Flannel
- CSI (Container Storage Interface):
应用需要保存临时数据,所以也需要存储,CSI 定义了存储相关的基本接口。常见的实现有:NFS、AWS EBS、GCE PD
通过模块化设计,将各种操作的具体实现细节从平台本身中抽离处理,k8s 获得了无与伦比的灵活性和通用性。
- 通过抽象出 CRI 接口,k8s 不需要知道容器运行的细节。不管是 linux 的容器、还是 windows 的容器,甚至是未来不知道什么平台的容器,甚至就不是容器,只要实现了 CRI 接口,都可以在 k8s 平台上进行统一调度和编排。
- 通过抽象出 CNI 接口,k8s 不需要知道配置网络的细节。你可以用 sidecar 全部转发流量,可以用 iptables 做路由转发,也可以用 vlan 或者什么其他的技术,根据平台选择最合适的,然后提供 CNI 接口,k8s 就可以不需要额外配置,直接享受到相对较优的网络配置。
- 通过抽象出 CSI 接口,k8s 不需要知道存储的细节。单机可以把文件存本地,集群可以用 nfs,ceph 等网络存储,上云了还可以用对象存储。而 k8s 不需要做什么更改,就可以直接使用。
总的来说,k8s 就相当于只是大脑,而各个其他接口的具体实现就是四肢,大脑通过控制四肢来实现相应的功能。并且,四肢还可以更换,可以更加的适应环境的变化~~(怎么赛博起来了)~~。
总之,kubernetes 就是现在的版本答案。(个人暴论)
目标 & 规划
首先,我要安装的是原版的 k8s,并且,手动修改的地方越少越好。
我会使用现在的最新版(1.30.2),进行安装,并且只做官方要求的步骤,尽量减少不必要的操作。
然后呢,在前几天努力之后,我已经获得了自带缓存加速的“docker”,所以我们可以不需要考虑网络的问题了(机器不需要有特殊的网络环境)。
容器运行时打算用 containerd,到时候直接安装 nerdctl,也就替代 docker 了。
网络插件打算用 Flannel,没什么理由,可能因为这个简单一点吧。
前期准备
我们开始吧。
我这里使用 3 台机器。
机器信息配置
首先是服务器的基本设置,我们需要
- 设置服务器时区
- 设置服务器 hostname
- 设置对时服务
(不同机器的 hostname 记得设置成不同的)
我是使用 cloud-init 做的初始化,下面是这一部分的脚本,这些基本配置就我们写好了让程序自己去搞,可以省很多事情。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#cloud-config
# 时区
timezone: Asia/Shanghai
# ntp 服务
ntp:
enabled: true
servers:
- ntp1.aliyun.com
# hostname
hostname: ${hostname}
|
我刚刚看了一眼,好像我把需要做的准备全部写成脚本了,那我就直接根据脚本讲吧。
我们安装官方的 教程,一步步来。
接着需要做的事情是:
安装容器运行时
我们使用 containerd,因为 nerdctl 的 full 版本自带 containerd 了,所以我们直接安装 nerdctl。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 安装 nerdctl
- wget https://github.com/containerd/nerdctl/releases/download/v1.7.6/nerdctl-full-1.7.6-linux-amd64.tar.gz -O /root/nerdctl.tar.gz -q
- tar -xvf /root/nerdctl.tar.gz -C /usr/local/
- rm /root/nerdctl.tar.gz
- ln /usr/local/bin/nerdctl /usr/local/bin/docker
- ln /usr/local/bin/nerdctl /usr/local/bin/dockerd
- ln /usr/local/bin/nerdctl /usr/local/bin/docker-compose
- systemctl enable --now containerd
# 开启 nerdctl 自动补全
- nerdctl completion bash | sudo tee /etc/bash_completion.d/nerdctl > /dev/null && sudo chmod a+r /etc/bash_completion.d/nerdctl
- echo 'complete -o default -F __start_nerdctl docker' >> /etc/bash.bashrc
# 自动开启 nerdctl 的 debug 模式
- echo "alias nerdctl=\"nerdctl --debug\"" >> /etc/bash.bashrc
|
这里从 github 上面下载 nerdctl 的 ful 安装包,网络问题可以自己手动下载再上传上去。
还顺便做了个链接到 docker,这样就可以直接像以前敲 docker 了。
启用 ipv4 转发
官方教程说要开,那就开吧。
1
2
3
4
5
6
7
8
9
10
11
|
# 启用 ipv4 转发
- echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
- sysctl -p
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
- |
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
- sudo sysctl --system
|
配置 cgroup 驱动
这里简单讲一下,cgroup 驱动有这两种:cgroupfs 和 systemd,根据我的理解:
cgroup 是用来负责容器的资源管理方面的,是容器运行时和 kubelet 打交道要用到的(和这两个组件有关)
k8s 好像是默认支使用 cgroupfs 的,但是现在大部分系统使用 systemd 启动,所以需要手动把容器运行时的 cgroup 的驱动换到 systemd。
对于 containerd 来说,就是修改一下配置文件。
对于 kubelet 来说,现在不用手动配置了。
在 Kubernetes v1.28 中,启用 KubeletCgroupDriverFromCRI特性门控 结合支持
RuntimeConfig CRI RPC 的容器运行时,kubelet 会自动从运行时检测适当的 Cgroup
驱动程序,并忽略 kubelet 配置中的 cgroupDriver 设置。
对于 kubeadm 来说,现在默认就是 systemd,我们不需要手动调整。
所以我我们就改一下 containerd 的配置吧
按照 k8s 文档 和 containerd 文档 的说明,我们要先生成默认的配置
1
2
|
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
|
然后找到
1
2
3
4
5
|
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = false
|
这一段,把SystemdCgroup = false改成SystemdCgroup = true。
额外的,我为了让我给 nerdctl 配置的缓存加速镜像仓库对 cri 也起作用,参考文档,还要把
1
2
|
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
|
这个地方的config_path = ""设置为config_path = "/etc/containerd/certs.d"
改完之后记得重启 containerd。
以上几步,用脚本完成就是:
1
2
3
4
5
6
7
8
9
10
|
# 生成 containerd 配置文件
- mkdir -p /etc/containerd
- containerd config default > /etc/containerd/config.toml
# cgroup 驱动程序 systemd
- sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 在 "[plugins."io.containerd.grpc.v1.cri".registry]" 行下面添加以下一行:
# [plugins."io.containerd.grpc.v1.cri".registry]
# config_path = "/etc/containerd/certs.d"
- sed -i '/\[plugins."io.containerd.grpc.v1.cri".registry\]/,/^\[/ s/config_path = ""/config_path = "\/etc\/containerd\/certs.d"/' /etc/containerd/config.toml
- systemctl restart containerd
|
安装 kubeadm、kubelet 和 kubectl
参考 官方文档,就照做就行了,我自己改了个使用清华源的脚本
1
2
3
4
5
6
7
8
9
10
11
12
|
# 使用 k8s 源 安装 k8s 工具
- curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
- echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] http://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
- apt-get -o pkgProblemResolver=true -o Acquire::http=true update -y
- apt-get -o pkgProblemResolver=true -o Acquire::http=true install -y kubelet kubeadm kubectl && apt-mark hold kubelet kubeadm kubectl
# 配置 k 为 kubectl 的别名
- echo "alias k=kubectl" >> /etc/bash.bashrc
# 开启 kubectl 自动补全
- kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null && sudo chmod a+r /etc/bash_completion.d/kubectl
- echo 'complete -o default -F __start_kubectl k' >> /etc/bash.bashrc
# 开启 kubeadm 自动补全
- kubeadm completion bash | sudo tee /etc/bash_completion.d/kubeadm > /dev/null && sudo chmod a+r /etc/bash_completion.d/kubeadm
|
引导 kubernetes
从这里开始,我们终于能够开始启动集群了。
参考 官方文档,我们要先选用一台机器作为 master,在 master 上面 init,然后把其他机器 join 进来。
kubeadm init
在上面的步骤都做好了的情况下,我们执行这一条命令,就可以直接 init master 节点了。
理论上是这样的,但实际上我们还要加一些参数
1
2
3
4
|
kubeadm init -v 5 \
--kubernetes-version=v1.30.2 \
--pod-network-cidr 10.244.0.0/16 \
--image-repository registry.aliyuncs.com/google_containers
|
-v 5:是为了显示更多信息,方便排查错误--kubernetes-version:指定一个版本进行安装,不指定的话会去请求这个地址去获取最新的小版本号,https://dl.k8s.io/release/stable-1.txt,但是网络原因,很慢或者根本获取不到,所以我们直接指定。--pod-network-cidr:这个一定要加,虽然对 kubeadm 没有什么影响,但是不加的话后面安装网络插件的话很麻烦(坑死我了),最好配置为 10.244.0.0/16,是 flannel 的默认配置,后面部署网络插件的时候就不需要再配置了。--image-repository:我这边是不需要的,如果网络不太行就加上--apiserver-advertise-address:这个是用来指定 master 的 ip 地址的,实测不填会自动获取当前网卡的地址,所以我没写。
然后我们运行之后最后会得到这样子的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.21.22.61:6443 --token tietbj.vxn6r8ftd2mblalp \
--discovery-token-ca-cert-hash sha256:dac57989db4852036f0e584fbba27edc8e2ac989876fe341ab0a3213f228a743
|
运行这一段给当前用户配置 kubectl 的 config
1
2
3
|
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
然后再找到这条命令,在其他机器上面运行就行了
1
2
|
kubeadm join 10.21.22.61:6443 --token tietbj.vxn6r8ftd2mblalp \
--discovery-token-ca-cert-hash sha256:dac57989db4852036f0e584fbba27edc8e2ac989876fe341ab0a3213f228a743
|
kubeadm join
然后在其他机器上面运行这条命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
root@ubuntu-63:~# kubeadm join 10.21.22.61:6443 --token tietbj.vxn6r8ftd2mblalp \
--discovery-token-ca-cert-hash sha256:dac57989db4852036f0e584fbba27edc8e2ac989876fe341ab0a3213f228a743
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.002688026s
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
|
出现This node has joined the cluster就代表连接成功了。
疑问
有些读者可能会有疑问:“我之前看过的教程,不都是要设置 hosts,关 swap,关 selinux,关防火墙的吗?”
emmm,我看到的教程也确实是这样的。不过现在官方文档上面没有要求这些了(以前确实要求关 swap)。
实践出真知,我也尝试了不调整这几个选项,结果是 kubeadm 在做预检的时候没有报错,集群也是可以正常搭建。
不过出于不想给自己添麻烦,我还是把这几个功能给关了,脚本在下面(不过确实是官方没有要求的)
1
2
3
4
5
6
7
8
9
|
# 禁用 swap
- swapoff -a
- sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# 关闭 selinux
- setenforce 0
- sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
# 关闭防火墙
- systemctl stop ufw
- systemctl disable ufw
|
验证
我们在 master 上面运行kubectl get nodes,就可以看到刚刚添加进来的节点了。
1
2
3
4
5
|
root@ubuntu-61:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
ubuntu-61 NotReady control-plane 2m15s v1.30.2
ubuntu-62 NotReady <none> 114s v1.30.2
ubuntu-63 NotReady <none> 111s v1.30.2
|
现在,我们集群的管理网络已经配置完毕(可以访问 api server 了),但是节点的状态是 NotReady,这是因为我们还没有安装网络插件。
我们输入 kubectl get pods -A 也可以看到
1
2
3
4
5
6
7
8
9
10
11
|
root@ubuntu-61:~# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-7db6d8ff4d-gdqpf 0/1 Pending 0 109s
kube-system coredns-7db6d8ff4d-jr2rn 0/1 Pending 0 109s
kube-system etcd-ubuntu-61 1/1 Running 0 2m3s
kube-system kube-apiserver-ubuntu-61 1/1 Running 0 2m3s
kube-system kube-controller-manager-ubuntu-61 1/1 Running 0 2m4s
kube-system kube-proxy-gfkjn 1/1 Running 0 103s
kube-system kube-proxy-jnbm6 1/1 Running 0 106s
kube-system kube-proxy-tl597 1/1 Running 0 109s
kube-system kube-scheduler-ubuntu-61 1/1 Running 0 2m3s
|
基本组件都是 Running 状态了,但是 coredns 还是Pending,这是也是因为确实网络插件的缘故。
安装网络插件
我们使用 flannel 作为网络插件,应用这个 yaml 即可完成配置,参考文档。
1
|
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
|
如果网络不太行的话,可以把这个 yaml 下载下来手动上传然后 apply。注意里面的镜像是 dockerhub 的,可能需要手动拉取镜像。
我们观察 pod 的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
|
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-4ppmv 1/1 Running 0 82s
kube-flannel kube-flannel-ds-bjc4s 1/1 Running 0 82s
kube-flannel kube-flannel-ds-sdxs9 1/1 Running 0 82s
kube-system coredns-7db6d8ff4d-gdqpf 1/1 Running 0 6m31s
kube-system coredns-7db6d8ff4d-jr2rn 1/1 Running 0 6m31s
kube-system etcd-ubuntu-61 1/1 Running 0 6m45s
kube-system kube-apiserver-ubuntu-61 1/1 Running 0 6m45s
kube-system kube-controller-manager-ubuntu-61 1/1 Running 0 6m46s
kube-system kube-proxy-gfkjn 1/1 Running 0 6m25s
kube-system kube-proxy-jnbm6 1/1 Running 0 6m28s
kube-system kube-proxy-tl597 1/1 Running 0 6m31s
kube-system kube-scheduler-ubuntu-61 1/1 Running 0 6m45s
|
看到多出来了 kube-flannel的命名空间和kube-flannel-ds 开头的许多 pod,当这些 pod 变为 Running 状态后,也就意味着网络插件安装好了。(可能要等一会)
然后再查看节点状态,就可以看到节点都 Ready 了。
1
2
3
4
5
|
root@ubuntu-61:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
ubuntu-61 Ready control-plane 52m v1.30.2
ubuntu-62 Ready <none> 30s v1.30.2
ubuntu-63 Ready <none> 49m v1.30.2
|
好的,以上,我们的集群的基础就已经搭建完成了。我们来做个测试吧。
测试 1
按照惯例,我们使用 nginx 镜像进行测试。
先执行这一条命令,创建一个名为 nginx,镜像为 nginx 的 deployment。
1
|
kubectl create deployment --image nginx nginx
|
然后我们执行这一条,创建一个类型为 nodeport 的 service,来暴露我们刚刚创建的 nginx deployment
1
|
kubectl create service nodeport nginx --tcp=80:80
|
我们使用 k get deployments,查看 nginx 的 deployment 是否已经就绪
1
2
3
|
root@ubuntu-61:~# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 33m
|
显示就绪之后,再使用 k get svc,查看暴露的端口
1
2
3
4
|
root@ubuntu-61:~# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 123m
nginx NodePort 10.107.186.239 <none> 80:32080/TCP 27m
|
我们看 nginx 行的最后面,80:后面的数字,就是在节点外部暴露的端口。
我们可以使用这个端口(我这里是 32080),在集群内部的任何一台机器上面访问到我们刚刚创建的 nginx 服务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
suyiiyii@ubuntu-63:~$ curl 127.0.0.1:32080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
|
可以看到我们成功的访问到了 nginx,也就意味着我们的我们的集群能够对外提供服务了。
测试 2
然后,我们可以来整一点好玩的。
k8s 是集群,那我们让集群干点活吧。
deployment 有一个属性,叫做 repilcas,代表这个 deployment 需要的副本数。默认值是 1,我们可以随意更改这个值,k8s 会帮我们自动扩缩容。
首先,我们再开一个终端,并且使用 watch 命令实时监控 (看戏):
然后,在原来的终端输入这样的命令调整副本数
1
|
kubectl scale deployment nginx --replicas=32
|
然后 k8s 就吭哧吭哧的去帮我们扩容了。
看看另一边的监控,是不是有点意思了。
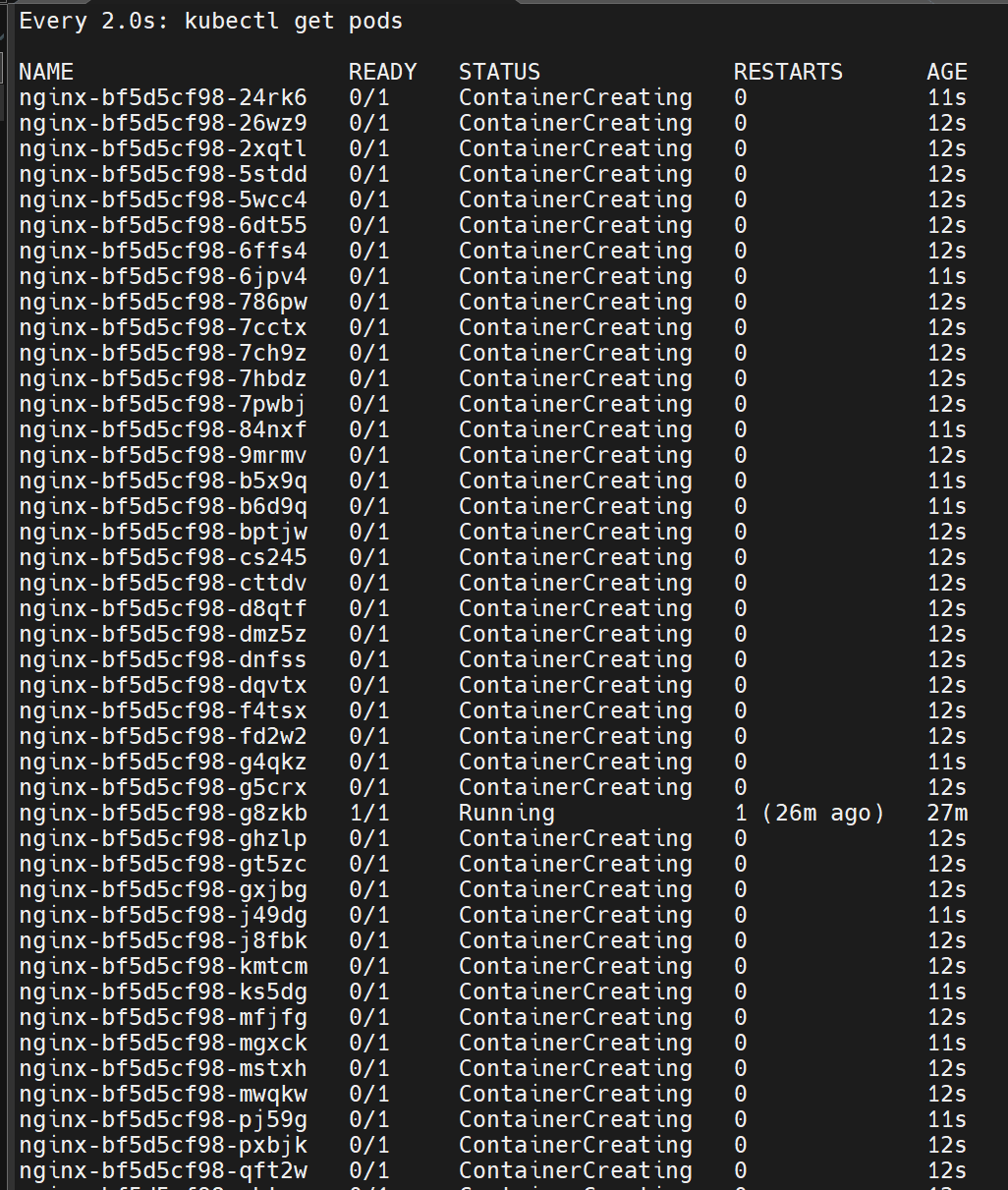
这里的副本数想改成多少都可以,pod 数量的上限是你机器的上限。
通过 service 去访问,会有一个简单的负载均衡,集群部署是不是很轻松呢。
最后可以使用 k delete 命令把创建的资源删除掉
1
2
3
4
|
root@ubuntu-61:~# kubectl delete deployments nginx
deployment.apps "nginx" deleted
root@ubuntu-61:~# kubectl delete service nginx
service "nginx" deleted
|
排查问题
这里给一些用来排查问题的方法
网络问题
首先考虑网络问题,尤其是镜像有没有拉取下来。
比如这就是拉取镜像的网络问题:
1
2
3
|
root@ubuntu-61:~# kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-bf5d5cf98-kklm4 0/1 ImagePullBackOff 0 13m
|
nerdctl 使用 --debug 选项,观察是从哪里去下载 image 了,有没有走镜像仓库。
kubeadm 开启 -v 5,查看详细信息,然后看是卡在哪一个镜像了。
使用kubectl events 看最近的事件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
root@ubuntu-61:~# kubectl events
LAST SEEN TYPE REASON OBJECT MESSAGE
52m (x2 over 52m) Normal NodeHasSufficientMemory Node/ubuntu-62 Node ubuntu-62 status is now: NodeHasSufficientMemory
52m Normal NodeAllocatableEnforced Node/ubuntu-62 Updated Node Allocatable limit across pods
52m (x2 over 52m) Normal NodeHasSufficientPID Node/ubuntu-62 Node ubuntu-62 status is now: NodeHasSufficientPID
52m (x2 over 52m) Normal NodeHasNoDiskPressure Node/ubuntu-62 Node ubuntu-62 status is now: NodeHasNoDiskPressure
52m Normal RegisteredNode Node/ubuntu-62 Node ubuntu-62 event: Registered Node ubuntu-62 in Controller
52m Normal Starting Node/ubuntu-62
52m Normal NodeReady Node/ubuntu-62 Node ubuntu-62 status is now: NodeReady
14m Normal ScalingReplicaSet Deployment/nginx Scaled up replica set nginx-bf5d5cf98 to 1
14m Normal Scheduled Pod/nginx-bf5d5cf98-kklm4 Successfully assigned default/nginx-bf5d5cf98-kklm4 to ubuntu-62
14m Normal SuccessfulCreate ReplicaSet/nginx-bf5d5cf98 Created pod: nginx-bf5d5cf98-kklm4
14m Warning Failed Pod/nginx-bf5d5cf98-kklm4 Failed to pull image "nginx": rpc error: code = NotFound desc = failed to pull and unpack image "docker.io/library/nginx:latest": failed to copy: httpReadSeeker: failed open: content at https://cr.suyiiyii.top/docker.io/v2/library/nginx/manifests/sha256:56b388b0d79c738f4cf51bbaf184a14fab19337f4819ceb2cae7d94100262de8?ns=docker.io not found: not found
12m (x4 over 14m) Normal Pulling Pod/nginx-bf5d5cf98-kklm4 Pulling image "nginx"
12m (x3 over 14m) Warning Failed Pod/nginx-bf5d5cf98-kklm4 Failed to pull image "nginx": failed to pull and unpack image "docker.io/library/nginx:latest": failed to resolve reference "docker.io/library/nginx:latest": failed to do request: Head "https://cr.suyiiyii.top/docker.io/v2/library/nginx/manifests/latest?ns=docker.io": dial tcp: lookup cr.suyiiyii.top on 127.0.0.53:53: no such host
12m (x4 over 14m) Warning Failed Pod/nginx-bf5d5cf98-kklm4 Error: ErrImagePull
12m (x6 over 14m) Warning Failed Pod/nginx-bf5d5cf98-kklm4 Error: ImagePullBackOff
4m47s (x39 over 14m) Normal BackOff Pod/nginx-bf5d5cf98-kklm4 Back-off pulling image "nginx"
|
可以看到具体的出错误的原因,比如我这里就是镜像仓库的域名解析出问题了,搞定之后就很顺利的创建好 pod 了。
容器问题
遇到很多次容器为 Error 状态。
使用 kubectl get po -A 查看容器的名字。
然后使用 kubectl logs -n <namespcae> <name>看容器的日志,看哪里出错了。
一般是有什么配置没搞好。
kubectl 都用不了
遇到过 api-server 都启动不起来,实际上其他组件有问题。
先用 ctr -n k8s.io c ls或者nerdcrt -n k8s.io ps 看容器信息,看看是哪一个组件出问题了。
再使用 cat /var/log/syslog 查看系统日志,containerd 会在里面打印一些日志,看看出错的在哪里。
最后发现是忘记配置 cgroup 了(捂脸),原来必须要手动改配置啊。。
总结
这次整套搞下来还是比较流畅的,因为之前有用 k3s 的经验以及昨天搞了一天 nerdctl。
最有作用的就是 pve + cloud-init + terraform的组合,真的不要太爽。先手动输入命令尝试,可以了就把命令写到脚本里面去,搞坏了就直接删掉机器,然后用写的脚本初始化机器,就回到刚刚出错前的状态了。
更重要的是,重置的整个过程都是全自动的,你就坐那里等一会就好了。要是以前,要给每一台机器:手动关机、等一会、恢复快照,等一会、开机、再等一会然后还要重复做刚刚没有快照记录到的地方。
现在的模式简直不要太爽,还有,你以前前面的步骤做错了,你要重新做,那后面的都要重新来,而我现在只要改一下脚本,把之前的删掉就行了。太牛了,深刻的体会到了 IaC 的强大。
感觉有点奇妙吧,好像最近做的事情都是环环相扣的,前面做的是现在的基础,因为之前折腾 cloud-init,大大降低了我试错的成本,所以我现在折腾 k8s 也格外方便。
总是就是非常爽🥰,明天再看看 ingress 和 lb。