前言
Prometheus 作为时序数据库保存数据,Agent 采集数据。Agent 会暴露一个 http 地址出来,然后在 Prometheus 里面配置,会定期去指定的地址拉去数据(pull 模式)
在这之后,用户使用 Grafana 查看的时候,就会自动从 Prometheus 中查询数据
一般 Prometheus 的 Agent 叫做 Exporter
Prometheus
安装
1
2
3
4
5
6
7
8
9
10
11
12
13
|
services:
prometheus:
ports:
- 9090:9090
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
image: prom/prometheus
extra_hosts:
- host.docker.internal:host-gateway
volumes:
prometheus-data:
|
这里暴露的端口,是向外提供服务的端口,也就 Grafana 导入数据时需要的端口
为了可以访问主机的端口,所以添加了这一条。在容器中访问 host.docker.internal 即可访问主机
1
2
|
extra_hosts:
- host.docker.internal:host-gateway
|
配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
|
这便是 Prometheus 的默认配置,粘贴过去即可,里面自带一个自身的数据监控
如果要添加监控配置的话,就在最下面 scrape_configs 这里添加配置就行了
Cadvisor
监控容器的各项指标
安装
参考文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
services:
cadvisor:
image: gcr.m.daocloud.io/cadvisor/cadvisor:v0.49.1
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
ports:
- 8080:8080
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg
|
配置
1
2
3
4
|
- job_name: cadvisor
static_configs:
- targets: ["host.docker.internal:8080"]
|
把这段配置复制到 Prometheus 的配置文件的 scrape_configs 项里面就行了
检查数据是否可用之后,就可以在 Grafana 里面添加面板
我用的是这个,Cadvisor exporter,导入之后直接可以用,非常方便
Node Exporter
监控节点的信息
安装
参考 官方文档
1
2
3
4
5
6
7
8
9
10
11
|
services:
node_exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
command:
- "--path.rootfs=/host"
network_mode: host
pid: host
restart: unless-stopped
volumes:
- "/:/host:ro,rslave"
|
官方没有使用端口映射,实际暴露的端口是 9100
配置
1
2
3
4
|
- job_name: "node"
static_configs:
- targets: ["host.docker.internal:9100"]
|
面板用这个,官方的 Node Exporter Full
Process Exporter
新增,类似于 Node Exporter,用于监控主机上面的进程
官方文档使用的配置文件,文档没说用命令行参数,所以这里也使用配置文件
本来想用点骚操作,像前面的 Grafana 那样子,改 entrypoint,然后里面用sh -euc,手动在运行之前把配置文件写进去。但是,不行,因为这镜像是 FROM scratch 的,根本没有 shell 环境
比较好一点的解决方法应该是写一个 Dockerfile,把配置文件 COPY 进去,但是也觉得麻烦了,所以还是直接文件挂载了,反正都是在 git 仓库里面的
1
2
3
4
5
6
7
8
9
10
|
services:
process-exporter:
image: ncabatoff/process-exporter:sha-e2a9f0d
ports:
- 9256:9256
privileged: true
volumes:
- /proc:/host/proc
- ./process-exporter.yaml:/config/config.yml
command: --procfs /host/proc -config.path /config/config.yml
|
配置文件用的这个,懒得选择,就全部都监控了吧
1
2
3
4
|
process_names:
- name: "{{.Comm}}"
cmdline:
- ".+"
|
同样的,在 Prometheus 里面配置
1
2
3
|
- job_name: process-exporter
static_configs:
- targets: ["host.docker.internal:9256"]
|
Tips
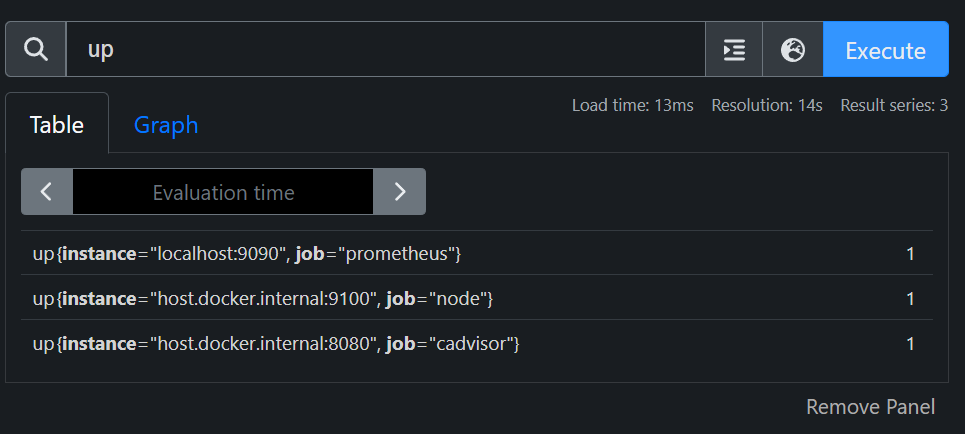
检查 Prometheus 配置是否正确
进入 Prometheus 的后台,查询 up,即可查询所有配置,行尾的数字代表 job 是否在线
添加多个 Exporter
不需要新增 job,只需要添加 Target 就行了
还是建议添加多个 job,面板应该要能够分别出来的
1
2
3
4
|
~~- job_name: "node"
static_configs:
- targets: ["host.docker.internal:9100"]
- targets: ["host.docker.internal:9101"] # New Node Exporter~~
|